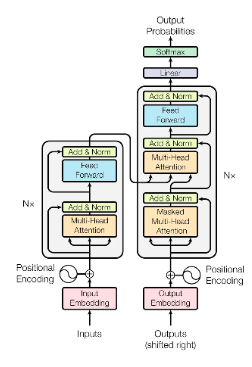
From Training Language Models to Training DeepSeek-R1
Reasoning Models #1 - An overview of training
You probably already understand the potential of reasoning models. Playing around with O1 or DeepSeek-R1 shows us these models' enormous promise. As enthusiasts, we are all curious to build something like these models.
We all start on this path, too. However, from the sheer scale of things, we get overwhelmed by where we can start. Rightfully so, earlier, around 6-7 years ago, we only needed an input and output to train a module. As someone who builds those models, we know that getting these two things right is hard. However, things are way more complex now. We need additional task-specific data for every task we do.
As an enthusiast, I want to dig deeper into these "reasoning" models and learn what they are and how they work. As a part of this process, I also plan to share everything I've learned as a series of articles to get a chance to discuss these topics with like-minded folks. So, please keep commenting and sharing your thoughts as you read this article.
Table of contents:
- What are reasoning models?
- How it all started.
- Why do they work?
- Training LLMs.
- The Age of the Classics.
- The age of RLHF
- The DeepSeek revolution
- Fine-tuning your model.
What's "reasoning" in these reasoning models?
How it all started.
Let's go back to when ChatGPT was first released and was running GPT-3.5-Turbo. Remember those days? Wasn't it very peaceful then?... People were very excited about the capabilities but found the responses inaccurate and weirdly limited in scope.
To try and get better outputs, people started adding a phrase at the end of the prompt. This phrase has many versions, but "think step by step" is the most common phrase.
It produced a few more tokens related to the user's prompt. But something magical started to happen. The accuracy of the answers increased. That's the start of the reasoning models. People realised that adding these "thought steps" would have a higher chance of obtaining the desired outputs. So, that's what they did. (By the way, people now technically call this "inference-time scaling".)
Why does this work?
Well, at its core, everything is still a language model. It just predicts a token based on the previous token. Suppose the previous token is a banking term (like cheque, cash, credit, etc). In that case, there's a very low probability for the new token to be a medical term (like anaesthesia, injection, syrup, etc.).
The "thought steps" essentially generate more tokens related to the user's input, decreasing the chance of randomness in the following tokens. Of course, as the models were developed, a few more things were added to this explanation, but ultimately, this is the fundamental logic.
These "reasoning" steps ultimately push the model to pick tokens closer to the user's input.
How these are trained.
The classics
In the earliest applications, life was very simple. We had a dataset, we mixed up a few layers into a network. We just trained this network on the dataset. Nice and easy.
However, things weren't working well. Except for some naive classification tasks, these approaches needed datasets in large (not the new "large" being terabytes, but old "large") sizes. And it was hard to have those available for every task. So what did people do?
We started building large, generalised datasets that can grasp the context. Then, we used these to train a base model and fine-tune it to relevant tasks. We've slowly realised that the small models cannot now learn from these large datasets. So, we started increasing the development of complex architectures to tackle these issues.
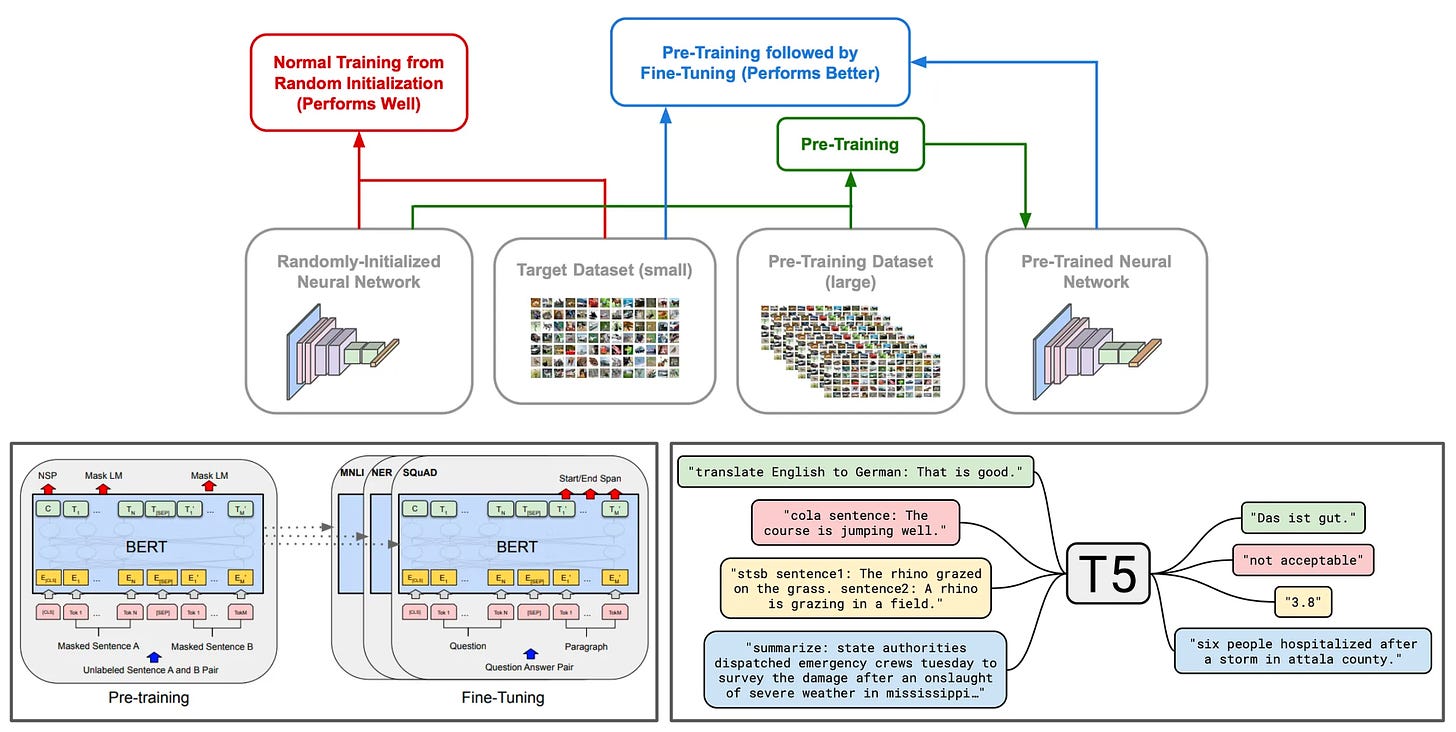
Ultimately, now we're facing models with billions of parameters and Terabytes of data to solve our tasks. Throughout the earlier stages of this process, the discriminative tasks like classification, regression, retrieval, etc improved rapidly. However, the output wasn't streamlined enough for generative tasks to be called "natural". We see too many repeating sentences, absurd text content, etc. That leads to people developing a new way of training.
The Age of RLHF
We never got to reach the "human-level" naturalism through supervised training. We needed a way to nudge the model to behave as closely as possible. To do that, we either need extremely large, filtered and natural datasets or a new way to train these models, which resulted in diminishing returns.
Or we had to use a different approach to train the model. This different approach turned out to be Reinforcement Learning. RL is a way of learning where the model is trained to behave through a series of penalties and rewards. In our case, we started by defining a reward measure and tuning the model to maximise this measure.
So, how do we determine what responses to reward? Well, we sit and rank multiple responses from the model. It's a time-consuming task, but ultimately, it has been done. Using these ranks, we train a simple module that predicts the rank based on the output generated.
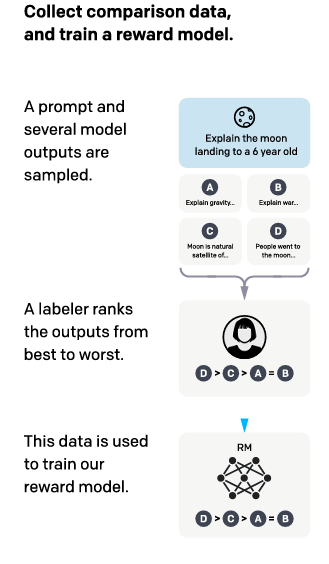
Using this module and the original model, we tune it using an algorithm called Proximal Policy Optimization (PPO). Similar to how we use gradient descent to decrease the losses, we use the gradient ascent approach to increase the reward for a model's output.
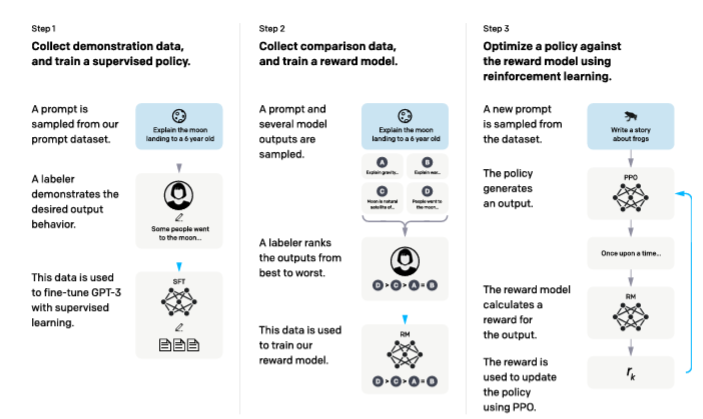
Of course, this is just based on the first paper discussing RLHF. There are multiple variations to this approach. For example, two reward models are developed in training Llama models instead of one. One focuses on the safety of the output, while the other focuses on "helpfulness".
There are even alternatives to PPO, such as Contrastive Preference Learning (CPL), Direct Preference Optimisation (DPO), etc., that are more efficient.
So...How does this matter to Reasoning models?
We won't use humans to rate prompts to train the models. However, we still follow the base approach of tuning the model on a reasoning dataset. This reasoning dataset should preferably have three columns: prompt, chain of thought (CoT), and completion. We fine-tune the model on this dataset and then use RL to improve the reasoning step further.
I plan to discuss the CoT construction and reward model decisions more soon! So, let's meet again there to go into detail!
The DeepSeek Revolution
Now, the reason the DeepSeek model had the hype it had was its cost. It was absurdly cheap for an entire training iteration. Of course, there are still claims that the pricing might not be accurate. However, they aren't actually among our worries for now.
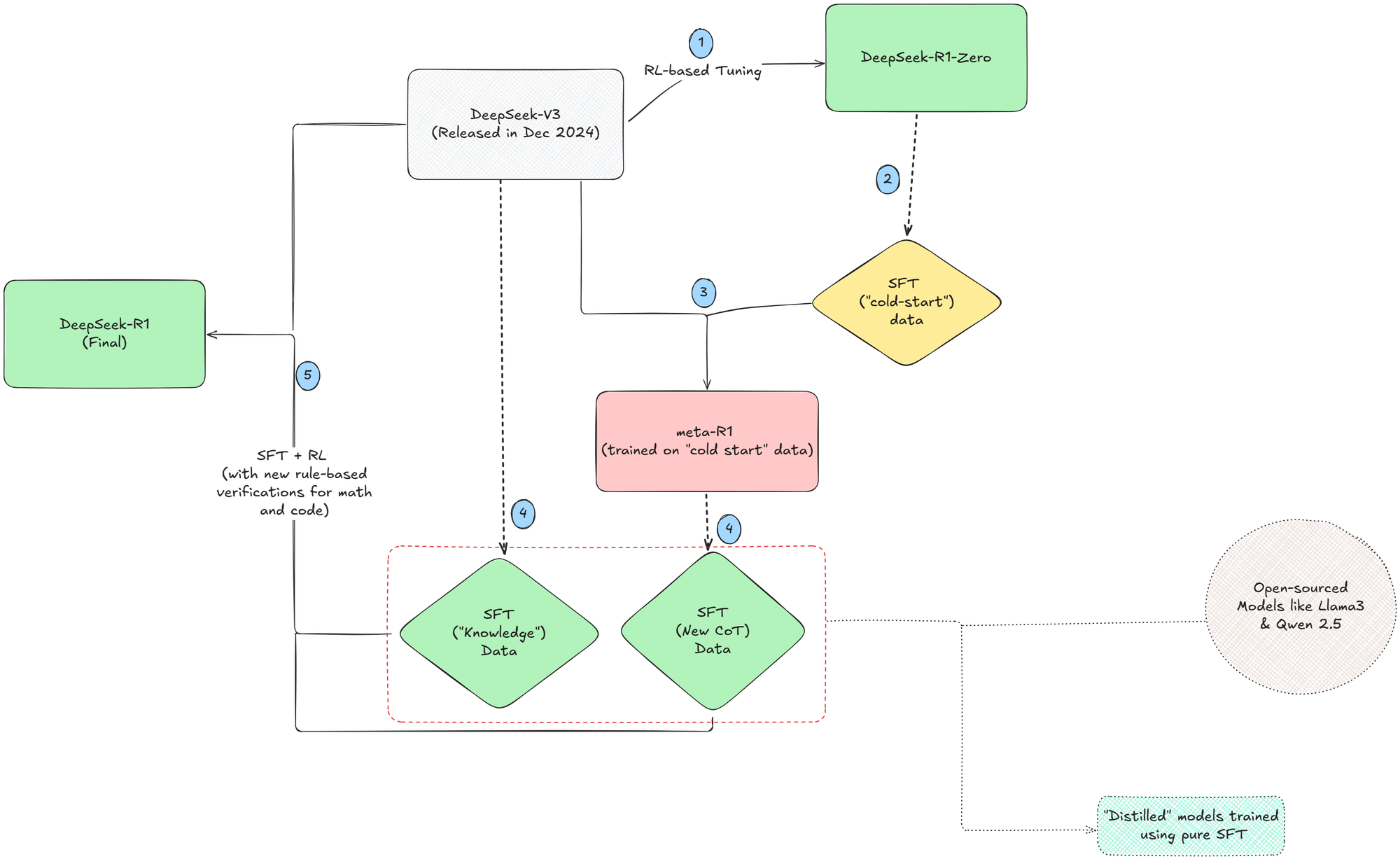
However, what concerns us is the way they've trained their models. Essentially, DeepSeek-R1 has three different training stages.
- RL-based Reasoning training
- Supervised Fine-tuning + RL with verifications
- Distillation.
Our concern for now is the first two stages. The distillation stage is used to train smaller 1.5B, 8B, 32B and 70B models, and these are topics for a later date.
1. Training DeepSeek-R1-Zero
Unlike the common approach of supervised fine-tuning + RL, the DeepSeek-R1-Zero is trained without any supervised dataset. Rather, the team directly tuned DeepSeek-V3 using RL.
The results from using RL are interesting because they highlight that reasoning emerges as behaviour from pure RL and not SFT. But there's an even more surprising aspect to this. That's the focus of the rewards that the model was trained on.
Rewarding based on reasoning is one of the direct approaches we'd use to improve the model's reasoning capabilities. However, directly converting this thought into numbers is very hard. So, we usually use a few proxies to approximate this result. Hence, the rewards were chosen in a way that indirectly act as a compass to the model's reasoning. These would be,
- Output Accuracy
- The output format accuracy
It is interesting to note that the feedback on the format and the output were enough for the model to learn basic reasoning skills.
Of course, that doesn't mean that R1-Zero is the best reasoning model out there. It just proves that reasoning is possible through pure RL. However, it has a far more important role in developing the larger and more generalising model.
2. Training DeepSeek-R1
The part that intrigued me most when reading the paper was not how the DeepSeek-V3 was fine-tuned into DeepSeek-R1. Rather, the data generation steps used to fine-tune the DeepSeek-V3 intrigues me.
The team first used the R1-Zero model to generate a set of Chain-Of-Thought texts and created a dataset. Using this setup, they trained a version of DeepSeek-V3. Let's call this meta-R1 for now. The RL-based tuning, this time, had a new "consistency reward model" along with two earlier reward models. This prevents the output from generating tokens in multiple languages and sticking to a single language.
Using this meta-R1, they generated a new set of CoT data of ~600k samples. They augmented this dataset with ~200k samples generated using DeepSeek-V3. Using this newly generated data, a base DeepSeek-V3 was tuned through Supervised Fine-Tuning followed by Reinforcement Learning. This newly tuned model is the 671B parameter model hosted on DeepSeek's website.
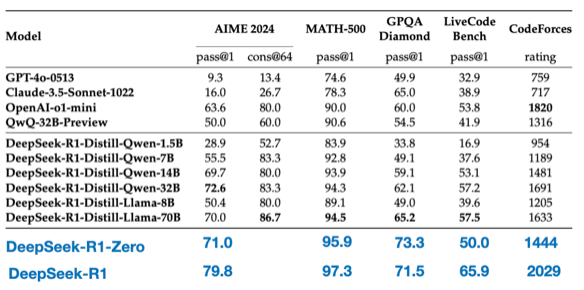
The result comparisons with DeepSeek-R1-Zero and DeepSeek-R1 on different mathematical and code benchmarks can be seen in the table below.
Fine-tuning your reasoning model
Now that we understand how things were developed, it's time to ask the most important question: How can we make it useful for our applications?
In this discussion, I'm still going to keep the discussion to a comprehensive level. The first and most important thing that we need is the dataset. Luckily, we do not need to follow in the footsteps of DeepSeek-R1. We can use the final model to generate a set of Chain-of-Thought prompts and use them to tune our models. Of course, it's a bit costly (requiring ~$650 for 50k samples using DeepSeek API). However, there is a surprisingly better option. People have worked on and published their reasoning datasets on HuggingFace repositories.
We can use the dataset to do what DeepSeek-R1 has done: train a smaller model directly using pure SFT. However, you can use the traditional SFT+RL approach using the trl library from HuggingFace.
To go into the code and generate a dataset or use the HuggingFace Dataset, Selecting the right model for the dataset and tuning and evaluating it is a topic we'll discuss in detail.
With that, I want to leave you to your own devices. It's time to explore and get an understanding of it on your own! However, I have given a few resources that I found very helpful for this process. I believe they are good starting points.
I hope you're able to find some value in this discussion. I'll for sure go into detail regarding what I've started soon. Stay tuned by following or subscribing to get the following articles immediately!
Thanks for reading till the end! Hope to see you soon! ✌️
References:
- Understanding Reasoning LLMs - Sebastian Raschka
- The Story of RLHF - Cameron R. Wolfe
- Illustrating Reinforcement Learning from Human Feedback - HuggingFace
- The Illustrated DeepSeek-R1 - Jay Alammar
- LLM Training: RLHF and Its Alternatives - Sebastian Raschka
- Training language models to follow instructions with human feedback - OpenAI
- Teaching Large Language Models to Reason with Reinforcement Learning - Meta