MLOps Notes -1: The Machine Learning Lifecycle
My Journey through the “MLOps Specialization” from DeepLearning.AI. This article describes the ML lifecycle along with the course overview.

MLOps Notes 1: The Machine Learning Lifecycle
Hello, everyone! And Happy New Year!
Akhil Theerthala here. Because of my personal obligations, I haven’t been able to write articles seriously until now. But finally, beginning today, I will start contributing once a week to my medium page!
I have yet to take any online courses in the last two months because I’ve been swamped with work. But now that I’ve started taking the Machine Learning For Engineering (MLOps) Specialization on Coursera. I’ll be sharing my notes on my medium. So, for the time being, check back every few days to catch up on my notes!
What is this course about?
Till now, we have seen the training part of machine learning models. Now it is time for us to see how we put them into production and the challenges and requirements we face in the process. i.e., this course deals with what happens outside the Jupyter notebook.
Example: Let us look at the case of scratch detection of mobile phones. We use a device to identify whether the phone has scratches or not.
- Edge Device: device living inside the factories
- Software: The program that controls the way edge device works.
In our case, we have inspection software that controls the camera, takes photos, and passes them to the control software.
- The control software calls an API, which passes the picture to the prediction server.
- The prediction server has the model, whose job is to predict whether there is a scratch.
- This result is sent back to the control software, which behaves in specified ways to classify the phone.
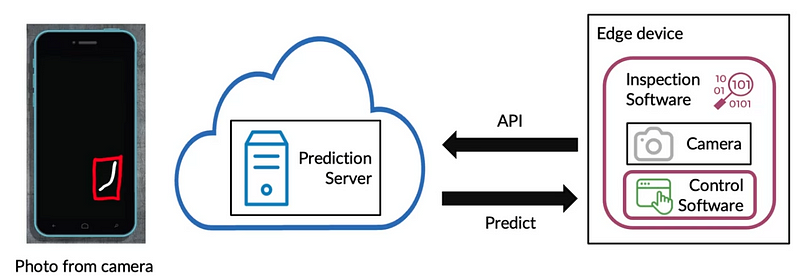
This is generally termed cloud deployment. There is another type of deployment called edge deployment, where the factory keeps running irrespective of the internet connection. The POC (proof of concept) is the ultimate model we build. But a lot is out there that makes people believe that this POC is only 5~10% of a production deployment.
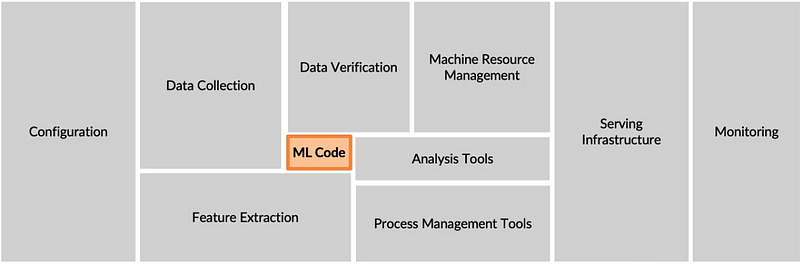
Well, the above image shows the entire components of an ml production deployment. In this course, the goal is to look into all the other processes. One of the easiest ways to look into these other components is to define a lifecycle for the machine learning project and explore each step when needed.
ML System lifecycle:
The generic lifecycle consists of 4 significant phases. We go through different processes or tasks in each step and move on to the next phase when we are satisfied with the current one. The parts are
- Scoping the project — Here, we define the project and the requirements and assumptions of the project we work on.
- Data — Based on the scoping, we define the required data, label them, and organize them.
- Modelling — We select and train a model using the final processed data and performing error analysis. This is the part we are most familiar with, and it happens in the Jupyter notebook.
- Deployment — After testing the model, it is sent to the first deployment into production. After the deployment, we monitor and maintain the entire production system based on user feedback.

The modelling and deployment steps are iterative in nature, i.e. these steps are constantly changed or might influence changes in the previous steps based on the intermittent observations.
Let us look at an example by using the steps in this cycle: Consider a Speech Recognition system where, based on the input audio clip, we will generate the transcript and a search function. In each step, we will ask ourselves a few questions which clarify what we need to do.
Step-1: Scoping
- Defining the project: Speech recognition can have many applications. One such application is speech recognition for voice search.
- What would be our key metrics in this case? (Completely problem dependent)
- Some of the key metrics include accuracy, latency, throughput, etc.,
- What is the target resource consumption? (In this step, we can see how the different systems are performing in the market and define a target)
So primarily, what we do in this step is theoretically define what we have to do and how we do it, along with making necessary assumptions. This part will be discussed in detail later in the course.
Step-2: Data
- Is the data labelled consistently?
- How much silence should we expect in the clip?
- How is the volume of different speakers normalized?
This step contains mostly Data scraping, processing, and feature engineering, which makes modelling with this data more manageable.
Step-3: Modelling
- Selecting the training model, i.e., choosing the code, hyperparameters, and data, gives us the model.
- Generally, in research work, the data is fixed, and the code is played around with. Whereas, in Product Teams, it is found that holding the code fixed and playing around with the data and the hyperparameters is regular and efficient.
- Rather than taking a model-centric approach, it is recommended to take pre-defined open-source models and then optimize them for the code and the data.
- Error analysis for the model generally helps us be more targeted in selecting the data and also verify that the model is working.
Step-4: Deployment
- Assuming that the edge device for the project is a mobile phone. We can write software that utilizes the modules in a mobile phone.
- Ideally, the software should use the device’s microphone and VAD (voice activity detection) module and send the speech data to the production server.
- The production server processes the request and sends the results according to the request. Generally, this production server is where our model pipeline is stored.
- Later, we have to monitor the system to see any concept drifts or other issues to ensure that the production tool delivers the value we envisioned.
The entire step is practically different and is highly application dependent. But the general essence of what we do is we try and deploy the model with a specific deployment pattern and later monitor it.
Suppose the model is performing according to our plan. In that case, we go ahead with the full-scale deployment, with constant monitoring for errors that can creep up.
In the first course, we will look backwards, starting from the deployment and then going each step back, i.e., the following article in the series will be on the Deployment part. We will also be looking into MLOps, which is an emerging discipline and comprises a set of tools and principles that support the best practices.
Thanks for stopping by! I will ensure that the following article comes out as soon as possible. So, keep an eye out for it! In the meantime, you can read my articles about my data analytics project or how the popular Deep Learning Specialization compares to Udacity’s Deep Learning Nanodegree.